这两天都在想如何生成唯一的iD的问题,下面是一些整理。
1.大部分文章都会介绍以下几种方案:
1.1 采用数据库自增ID
优点:
- 实现简单,ID有序
缺点:
- 主要问题就在于,当场景需要对ID需要进行集成和切割时,如何保证ID不冲突。
- 例如: 新旧系统都存在的时候。
- 例如: 需要插入指定ID进行记录的时候。
1.2 UUID
优点:
- 本地生成,生成简单,性能好,没有高可用风险
缺点:
- 长度过长,存储冗余,且无序不可读,查询效率低
1.3 Redis生成ID,这个方法没试过,需要用redis的时候试试
优点:
- 不依赖于数据库,灵活方便,且性能优于数据库;有序,对分页或者需要排序的结果很有帮助。
- 对于分布式来说,可以初始化每台redis的初始值,步长,然后按照步长递增。
1
2
3
4
5
A:1, 6, 11, 16, 21
B:2, 7, 12, 17, 22
C:3, 8, 13, 18, 23
D:4, 9, 14, 19, 24
E:5, 10, 15, 20, 25
缺点:
- 对于压根不用redis的系统,需要引入额外组件。
1.4 snowflake算法,本文重点。
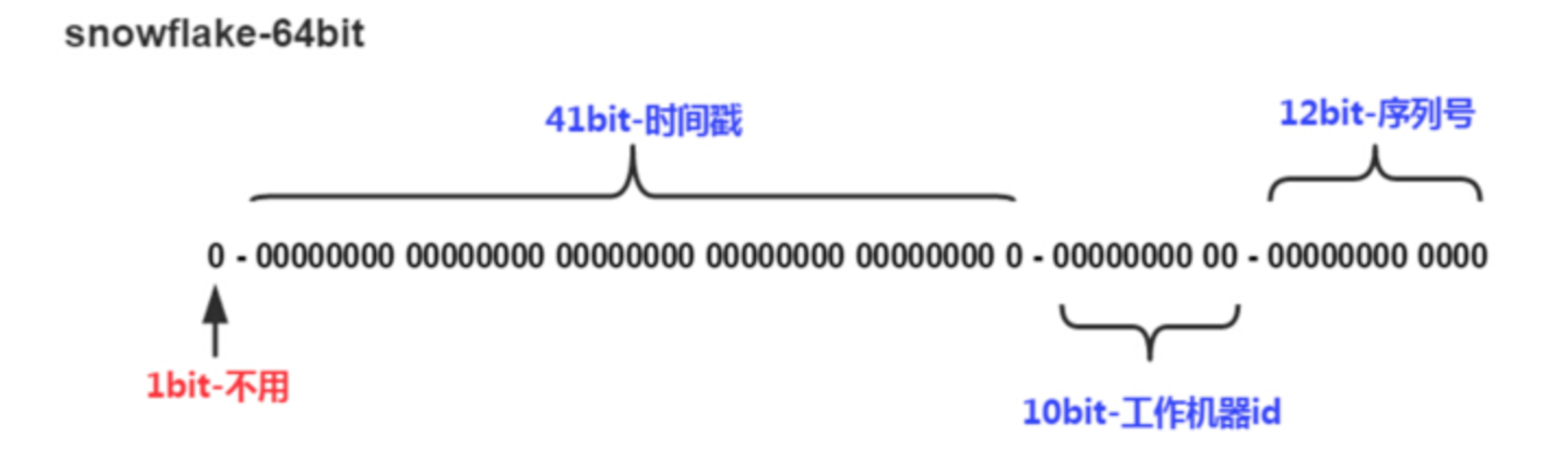
- 1bit:留着备用
- 41bit: 时间戳:2的41次方为:2199023255552,假设当前时间为2020-04-18 01:38:18,转为时间戳1587145098000, 1587145098000+2199023255552=3786168353552,3786168353552代表2089-12-23 17:25:53,可以使用69年。
- 10bit:记录机器id,2的10次方是1024台,机器可以根据地域和工作机器在进行细分。
其实机器iD和时间戳都可以根据自己的需求定义,41位呢是因为刚好可以塞到数据BIGINT类型中。
接下来是python中的实现
1.定义基本的变量,分布区域,机器码,序列的bit
1
2
3
region_id_bits = 2 #机器分布的区域分配的bit -> 2**2=4
worker_id_bits = 10 # #机器分配的bit ->2**10=1024
sequence_bits = 11 # 序列分配的bit ->2**11=2028
2.计算最大值,及能取的最大值
1
2
3
4
# 能取的最大值,位运算+1
MAX_REGION_ID = -1 ^ (-1 << region_id_bits)
MAX_WORKER_ID = -1 ^ (-1 << worker_id_bits)
SEQUENCE_MASK = -1 ^ (-1 << sequence_bits)
3.定义一个元年,想Twitter就是1288834974657,时间戳从-11开始,序列号为0
1
2
3
self.twepoch = 1288834974657
self.last_timestamp = -1
self.sequence = 0
4.生成id的函数
- 判断时间是否同步,分布式的机器时间必须一致,若是单台机器则没这问题。
- 判断当前序列号是否超出最大值:是则寻找新的时间戳,不是则序列号+1。
- 最后对时间戳,区域id,机器id和序列号,进行偏移然后拼接。
1
2
3
4
5
6
7
8
9
# 这里可能会点看不太懂,其实就是用左移动运算符(<<)填充0。
# 把时间戳填充成64位
# 把区域id,机器id同样操作
# 最后使用或运算将他们加起来,形成一个64bit长度的唯一id.
return (
(timestamp - self.twepoch) << Snowflake.TIMESTAMP_LEFT_SHIFT
|(padding_num << Snowflake.REGION_ID_SHIFT)
|(self.worker_id << Snowflake.WORKER_ID_SHIFT)
|self.sequence )
最后附上完成的代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
class Snowflake(object):
region_id_bits = 2
worker_id_bits = 10
sequence_bits = 11
# 能取的最大值,位运算+1
MAX_REGION_ID = -1 ^ (-1 << region_id_bits)
MAX_WORKER_ID = -1 ^ (-1 << worker_id_bits)
SEQUENCE_MASK = -1 ^ (-1 << sequence_bits)
# 移位偏移计算,计算位数,用于之后的异或运算
WORKER_ID_SHIFT = sequence_bits
REGION_ID_SHIFT = sequence_bits + worker_id_bits
TIMESTAMP_LEFT_SHIFT = (sequence_bits + worker_id_bits + region_id_bits)
def __init__(self, worker_id, region_id=0):
self.twepoch = 1288834974657
self.last_timestamp = -1
self.sequence = 0
assert 0 <= worker_id <= Snowflake.MAX_WORKER_ID
assert 0 <= region_id <= Snowflake.MAX_REGION_ID
self.worker_id = worker_id
self.region_id = region_id
self.lock = threading.Lock()
def generate(self, bus_id=None):
return self.next_id(
True if bus_id is not None else False,
bus_id if bus_id is not None else 0
)
def next_id(self, is_padding, bus_id):
with self.lock:
timestamp = self.get_time()
padding_num = self.region_id
if is_padding:
padding_num = bus_id
if timestamp < self.last_timestamp:
try:
raise ValueError(
'Clock moved backwards. Refusing to'
'generate id for {0} milliseconds.'.format(
self.last_timestamp - timestamp
)
)
except ValueError:
print(sys.exc_info()[2])
if timestamp == self.last_timestamp:
self.sequence = (self.sequence + 1) & Snowflake.SEQUENCE_MASK
if self.sequence == 0:
timestamp = self.tail_next_millis(self.last_timestamp)
else:
self.sequence = random.randint(0, 9)
self.last_timestamp = timestamp
print(timestamp - self.twepoch << Snowflake.TIMESTAMP_LEFT_SHIFT)
print(padding_num << Snowflake.REGION_ID_SHIFT)
print(self.worker_id << Snowflake.WORKER_ID_SHIFT)
print(self.sequence)
return (
(timestamp - self.twepoch) << Snowflake.TIMESTAMP_LEFT_SHIFT |
(padding_num << Snowflake.REGION_ID_SHIFT) |
(self.worker_id << Snowflake.WORKER_ID_SHIFT) |
self.sequence
)
def tail_next_millis(self, last_timestamp):
timestamp = self.get_time()
while timestamp <= last_timestamp:
timestamp = self.get_time()
return timestamp
def get_time(self):
return int(time.time() * 1000)